Enterprise AI/ML Testing Services and Quality Engineering Solutions
Artificial Intelligence (AI) and Machine Learning (ML) systems introduce unique quality challenges that traditional software testing approaches cannot fully address.
ELAARSON helps organizations validate the accuracy, reliability, security and performance of AI-powered applications, Generative AI platforms, Large Language Models (LLMs), chatbots and intelligent automation solutions.
Our AI Testing Services include:
By combining Quality Engineering, Automation Testing, API Testing and AI Assurance practices, ELAARSON enables organizations to confidently deploy AI solutions while reducing business risk and accelerating innovation.

While machine learning models are at the core of AI-powered systems, they represent only a small portion of the overall solution. The majority of effort lies in managing data pipelines, integrations, validation processes, monitoring frameworks and supporting infrastructure required to ensure reliable AI operations.
At ELAARSON, our AI/ML Testing Services focus on two critical pillars of AI quality assurance: comprehensive data validation and rigorous testing of machine learning models and intelligent applications. Together, these areas help organizations improve model accuracy, reduce business risk and ensure successful AI deployments.
Data Validation, Bias Detection and AI Model Quality Assurance
Data is the foundation of every Artificial Intelligence (AI) and Machine Learning (ML) solution. The quality, accuracy and diversity of training and testing datasets directly influence the reliability and effectiveness of AI-powered applications. Unlike traditional software systems, AI models continuously depend on data quality for learning, prediction and decision-making.
At ELAARSON, we help organizations validate training datasets, testing datasets and production data pipelines to ensure AI systems deliver accurate, consistent and trustworthy outcomes. Our AI/ML Testing Services focus on identifying data quality issues, eliminating hidden biases and validating model behavior before deployment into production environments.
One of the biggest challenges in AI systems is bias within training and testing datasets. If data is incomplete, unbalanced or skewed toward specific outcomes, the resulting model may generate inaccurate predictions, unfair recommendations or unreliable business decisions. Therefore, validating the quality and representativeness of datasets is a critical component of AI Quality Engineering.
ELAARSON evaluates datasets for completeness, consistency, duplication, imbalance, hidden correlations and other factors that may negatively impact model performance. We also assess AI models for overfitting, underfitting, prediction drift and accuracy degradation to ensure long-term reliability after deployment.
By combining Data Validation, AI Model Testing and Quality Engineering best practices, organizations can significantly reduce risk, improve model performance and confidently deploy AI-powered applications at enterprise scale.
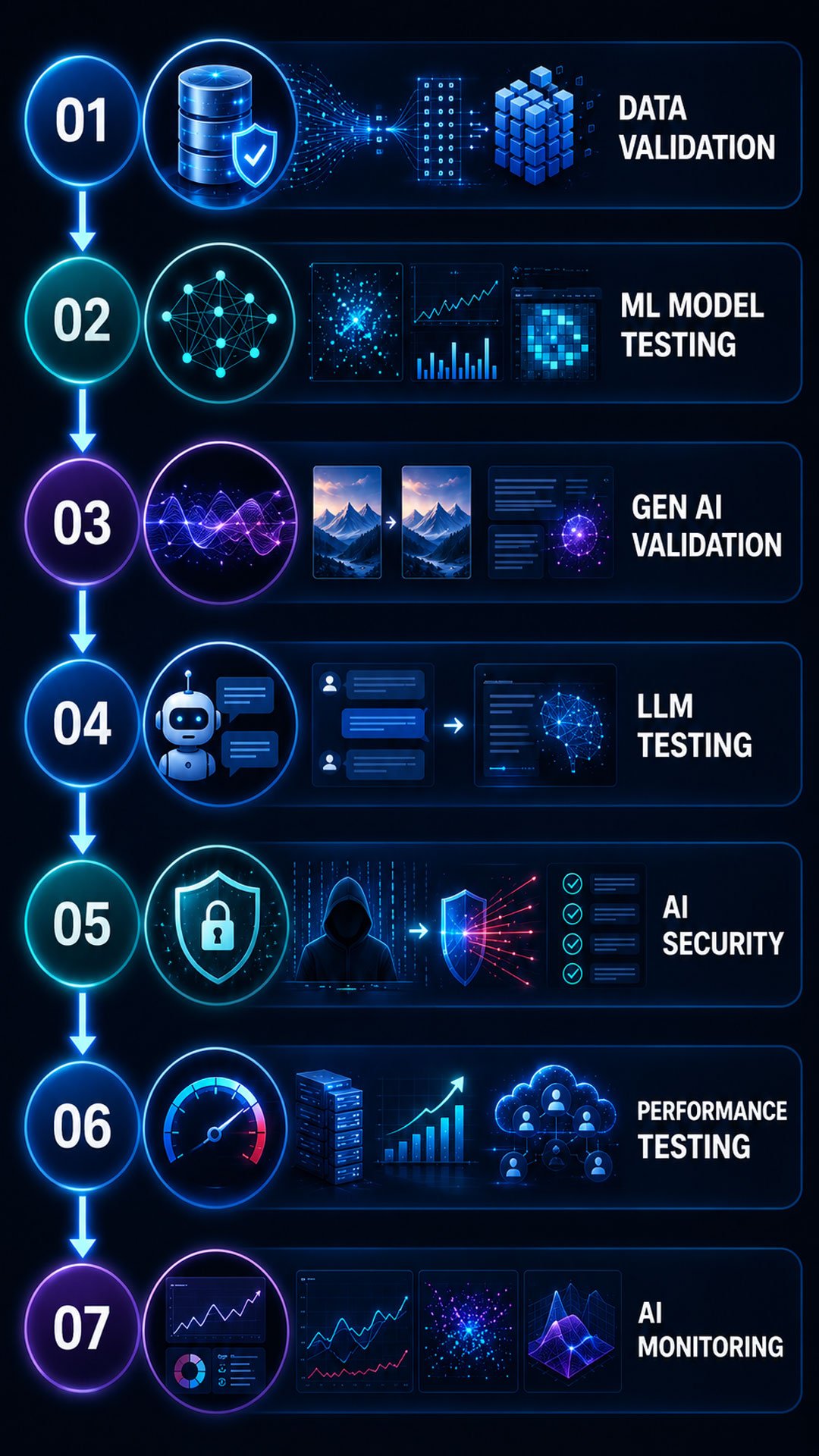
Key Areas of AI/ML System Testing
Modern AI applications require specialized testing approaches that validate model behavior, data quality, integrations, security and real-world performance. ELAARSON applies a comprehensive AI Quality Engineering framework to ensure intelligent systems remain reliable, scalable and business-ready.
Unlike traditional software systems, AI models continuously evolve as data, business conditions and user behavior change over time. Our testing approach combines model validation, data verification, performance assessment and production monitoring to ensure AI systems deliver accurate, secure and trustworthy outcomes throughout their lifecycle.
Request Pilot Project Terms & Condition Privacy Policy
Copyright © ELAARSON Industries 2019 - 2026. All rights reserved.